
Amy Tobey’s talk at Failover Conference in 2020 entitled, “The Future of DevOps is Resilience Engineering” is a good place to start if you’ve stumbled upon this space as “the place” where the future is likely to happen. It’s available on YT below, and you can read a terrific summary by Hannah Culver over on blameless.com.
Tom Geraghty writes about this topic on his blog and points to what is the seminal text entitled “Resilience Engineering” by Erik Hollnagel, David Woods, and Nancy Leveson. Geraghty paraphrases the authors:
… resilience is about what a system can do — including its capacity to anticipate, synchronize, be ready to respond, proactively learn …
Tom Geraghty
Nancy Leveson’s later paper in 2017, “Engineering Resiilence into Safety-Critical Systems” is an interesting branch where she introduces the idea of STAMP as a model for thinking about accidents: “Systems-Theoretic Accident Modeling and Processes.”
System behavior in system dynamics is modeled by using feedback (causal) loops, stock and flows (levels and rates), and the non-linearities created by interactions among system components. In this view of the world, behavior over time (the dynamics of the system) can be explained by the interaction of positive and negative feedback loops [14]. The models are constructed from three basic building blocks: positive feedback or reinforcing loops, negative feedback or balancing loops, and delays. Positive loops (called reinforcing loops) are self-reinforcing while negative loops tend to counteract change. Delays introduce potential instability into the system.”
—Leveson et al
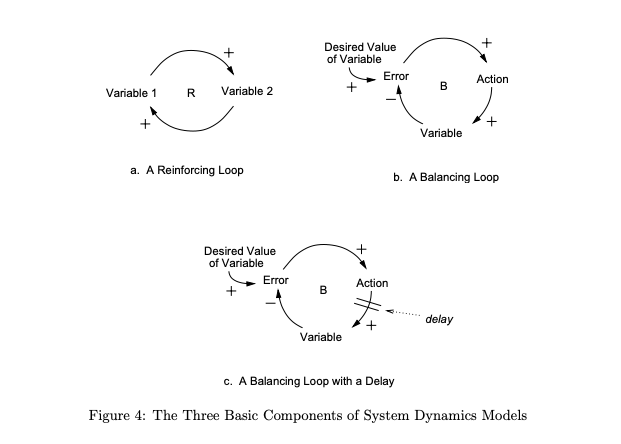
Chris Riley on devops.com summarizes resilience engineering as requiring “the resilience stack” which he defines as including:
- “Observability and/or monitoring tool.
- Incident response tool.
- On-call strategy documentation.
- Post mortem process and documentation.
- Documented processes including recommend response steps.
- Path to automation.” [ref]
Riley places chaos engineering at a level *above* resilience engineering — in other words, resilience engineering is table stakes for any organization that is managing amidst complexities.
As for how resilience engineering and DevOps interrelate, I guess I’m a strong believer after having written How To Speak Machine and having worked in the world of critical event management for both digital and physical systems (i.e. devops and emergency management) — that this idea of “constant improvement” is something that lies at the heart of humans’ desire to adapt. Large systems, by their very nature, take on much more wear because of their large surface area; plus they wear themselves down due to the complicate machinery that’s running them. There are constant endogenous risks to a large software system — much like you’d say a large organization carries, too, with its inherent operational complexities. We make software systems all the time in the world of speaking machines and deploy them at scale (i.e. DevOps universe) at a much higher than the rate by which we make large scale organizations that operate in the real world. So there’s something fundamental about the world of DevOps that links with the way of resilience engineering that isn’t just limited to the digital world, IMHO.
In closing, I strongly suggest reading Geraghty’s summary of conclusions on the topic of resilience engineering because he gets to the heart of the matter: people. It’s the people who are able to find a path to adaptiveness. In other words, resilience doesn’t happen by default. It happens because a committed group of people care to “do the work” of making/engineering something important to become more resilient.
I’m going to keep plowing away at this topic during 2022 … let’s see where this goes! —@johnmaeda in January 1, 2022
PS Just found a terrific 2020 paper by Professor Leveson here on what she terms “Safety III.” Here’s one of the key highlights I enjoyed from her paper:
It is the engineer’s responsibility to outline the hazards (risks) but only the stakeholders can determine
the fate of the system.”
—Nancy Leveson